Free Javascript Rendering SEO Crawler Update 1.1.22
Version 1.1.22 focuses on improving crawl workflow reliability, multi-domain analysis, and overall stability when performing technical SEO audits across modern websites.
This update refines how CrawlRhino handles domain switching, crawl history, and real-time interface updates while continuing to improve CrawlRhino’s capabilities as a free SEO crawler with JavaScript rendering support.
As more websites rely on dynamic frameworks and client-side rendering, accurate rendered-page analysis has become essential for technical SEO auditing.
Key Highlights
- Improved domain switching and crawl history handling
- Enhanced support for scanning multiple domains in one session
- Fixed data binding crash when switching domains
- Improved TreeView syncing and root domain detection
- Improved crawl reset behaviour between scans
- More stable UI updates during crawling
- Refined status-based row highlighting
- Continued improvements to JavaScript rendering workflow
These updates strengthen CrawlRhino as a reliable desktop SEO crawler and website audit tool for analysing both static and dynamically rendered websites.
JavaScript Rendering Improvements for Modern SEO Audits
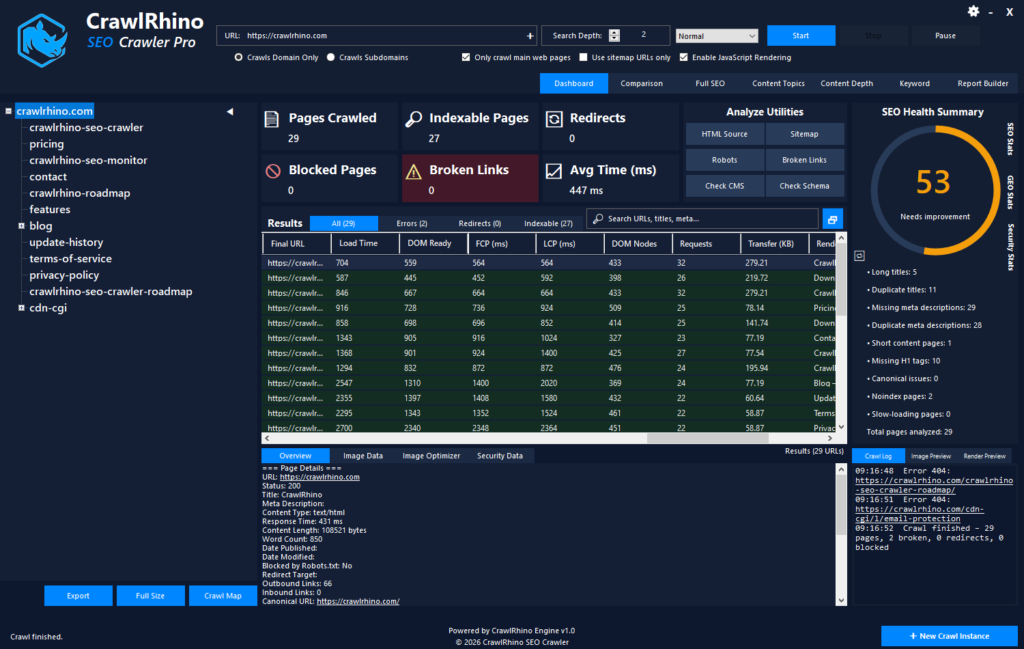
Modern websites built with React, Next.js, Vue, and other frameworks often rely heavily on client-side rendering. Traditional crawlers may miss important SEO elements unless pages are fully rendered.
CrawlRhino includes optional JavaScript page rendering, allowing users to analyse the fully rendered DOM rather than raw HTML responses.
The CrawlRhino’s rendering engine allows users to render web pages for SEO analysis, providing a clearer view of what search engines actually process.
This enables CrawlRhino to function as a:
- free SEO crawler with JavaScript rendering
- rendered page SEO analysis tool
- technical SEO crawler for dynamic websites
- browser-based rendering audit tool
With rendering enabled, CrawlRhino can analyse:
- rendered page titles and meta descriptions
- rendered H1 headings detected after scripts load
- final URLs following JavaScript redirects
- page performance metrics (FCP, LCP, DOM Ready)
- DOM structure after JavaScript execution
- request counts and transfer size insights
This makes CrawlRhino a practical desktop SEO crawler with browser rendering, helping users audit dynamic websites without relying on cloud-based tools.
Improved Multi-Domain Crawling Workflow
SEO professionals frequently analyse multiple websites during a single session. Version 1.1.22 improves how CrawlRhino manages multi-domain workflows.
Enhancements include:
- smoother switching between crawled domains
- safer history loading
- improved dataset consistency
- better handling of multiple active crawl sessions
These changes make CrawlRhino more efficient as a technical SEO audit software for agencies and consultants.
Enhanced Crawl History Handling
Crawl history has been refined internally to improve reliability when reloading previous scans.
Improvements include:
- safer dataset restoration
- improved TreeView synchronization
- more reliable domain recognition
- cleaner project switching behaviour
Users can now reopen previous website audits more confidently without losing analysis data.
Fixed Domain Switching Stability Issue
A rare issue that could sometimes cause a data binding crash when switching domains has been resolved.
Navigation between crawled websites is now stable, ensuring datasets remain intact during analysis.
This improves reliability when using CrawlRhino as a website SEO crawler for large audits.
Improved TreeView Syncing & Root Domain Detection
TreeView navigation now better understands domain structure and crawl scope.
Updates include:
- improved root domain detection
- clearer handling of sub-path crawls
- better synchronization between UI and crawl data
This results in a smoother workflow when analysing complex website structures.
Better Crawl Reset Between Scans
Starting a new crawl now fully resets internal crawl state, preventing previous data from affecting new audits.
Benefits include:
- cleaner scan initialization
- improved stability across repeated crawls
- more predictable crawl behaviour
Especially useful during repeated technical SEO testing and debugging workflows.
More Stable UI Updates During Crawling
Live crawl updates have been optimized to improve responsiveness during large website scans.
Users should notice:
- smoother interface updates
- fewer UI refresh interruptions
- improved stability during heavy crawling
- better performance when analysing thousands of URLs
Why These Improvements Matter
Modern technical SEO requires analysing both static HTML and dynamically rendered content.
By combining stability improvements with JavaScript rendering capabilities, CrawlRhino continues evolving into a powerful:
- free SEO crawler for Windows
- JavaScript rendering SEO crawler
- technical website audit tool
- local desktop alternative to cloud crawlers
Improved reliability means faster audits and fewer interruptions during real-world SEO workflows.
Version 1.1.22 — Summary
New in this release:
- Improved domain switching
- Enhanced multi-domain crawling
- Fixed data binding crash
- Improved crawl history handling
- Better TreeView synchronization
- Improved crawl reset logic
- UI stability enhancements
- Refined row highlighting
- Continued JavaScript rendering improvements
Continuous Development
CrawlRhino SEO Crawler continues active development focused on performance, usability, and modern website analysis capabilities.
Future updates will continue expanding rendering analysis, crawl intelligence, and technical SEO auditing features while maintaining fast local performance without subscriptions or usage limits.
Download CrawlRhino SEO Crawler
Download CrawlRhino SEO Crawler:
More updates coming soon.